在前一篇的文章指出,在醫療產業中的監管文獻有兩篇。然而這兩篇的內容其實都不是針對ML的案例而寫的。在MDCG的另一個規範MDR/IVDR 框架下的指南當中,才有納入ML的考量。
從ML系統可以利用現有的醫療資料替病患提供更有效、更有見解的醫療協助。但模型本身的決策則需要能夠被醫師或其他從業人員所理解。因此醫療器材製造商應該加強可解釋度以及專案的透明度。並且讓臨床評估當作是模型、醫療器械開發的過程之一,在上市之後也持續監督資料與使用者回饋。
Oravizio是一種醫療設備軟體服務,是一間芬蘭公司,可提供與髖關節(全髖關節置換術,THA)和膝關節(全膝關節置換術,TKA)置換手術相關的患者級別風險的訊息。儘管 THA 和 TKA 是成功率高的高效外科手術,但它們存在一定的不良事件風險。THA 和 TKA 手術後最常見的不良事件包括再次手術、假體關節感染和其他可能導致死亡的嚴重醫學併發症。成功的手術可以顯著提高患者的生活質量並降低社會成本。
在這個背景設定下,Oravizio有三個模型進行相關的預測:(1)手術後 1 年內有感染風險。(2)手術後 2 年內再次手術的風險。(3)手術後 2 年內有死亡風險。透過這三個模型,患者可以更好的理解手術風險和預期結果。
在第一個版本當中資料包括30,000 多筆患者記錄。然而在這些資料當中,還需要合併、判斷是否失效等等。光是第一個階段就需花非常大的力氣來整理這些資料到資料湖(data lake)當中。
在特徵的挑選上,資料包含從2008年開始收集的750 多個操作前變量。例如:一般客戶背景(年齡、性別、BMI)、藥物、實驗室值、診斷、患者報告和衍生變量。在這部分則需要結合醫師的專業知識,以及過去的研究文獻和計算方法,來挑選適當的特徵變量。這些資料當中,2008-2015年的資料用於訓練,2016-2018年的資料用於測試。
使用的挑選方式:LASSO, Ridge regression, 以及Elastic net。而建置模型的部分則使用了:Logistic regression, Decision tree-based methods (Random forest)., Gradient boosting methods (XGBoost), Weibull/Cox survival mode。整個開發流程也獲得 ISO 13,485、 IEC 62304、ISO 14971 和 IEC 62366-1的合格認證。
關於軟體開發與合規審核的合作流程可以參考這份流程圖: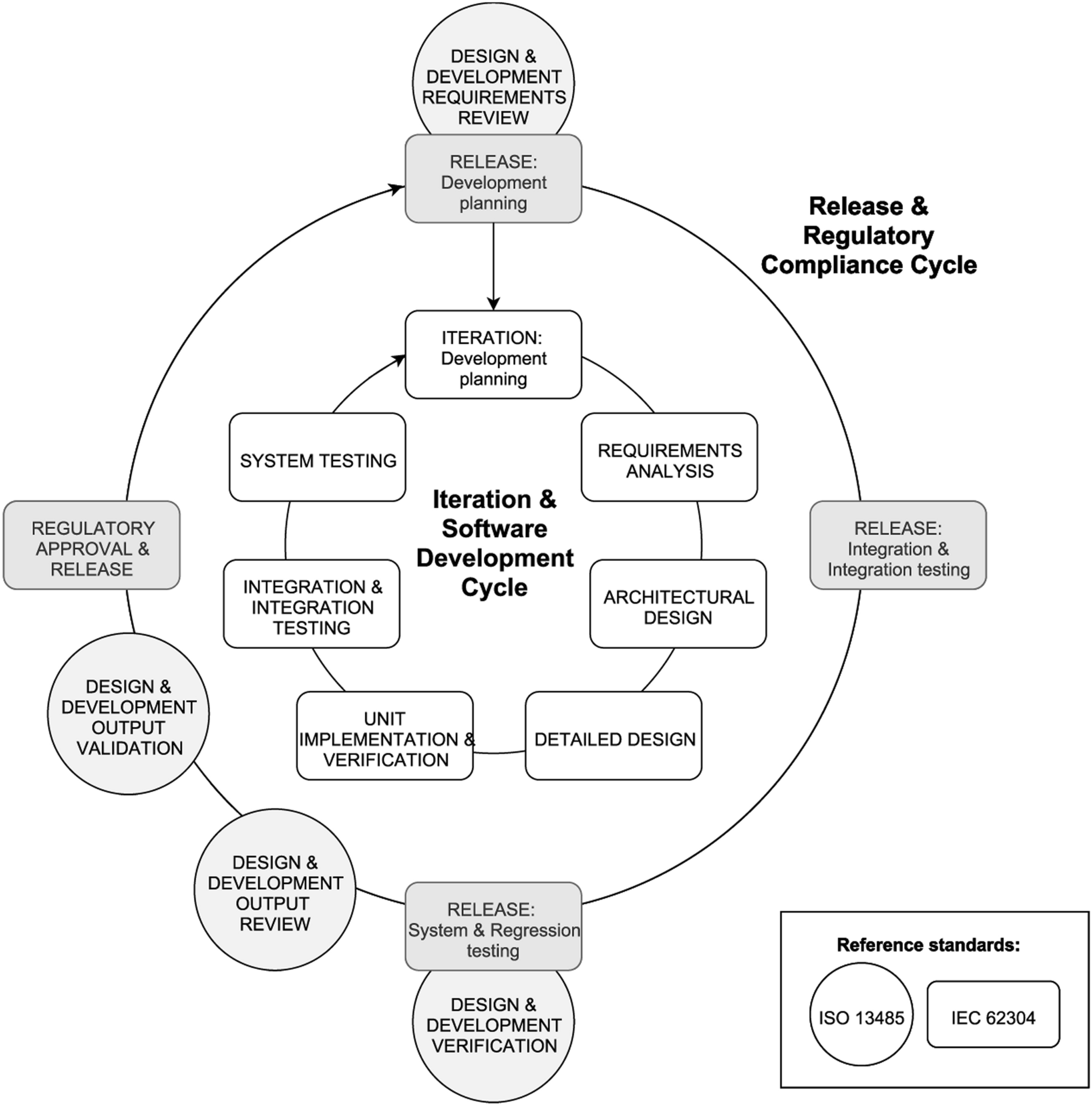
*圖片來源:Towards Regulatory-Compliant MLOps: Oravizio’s Journey
理想與現實總是有一些差距,然而在專案的實作當中,跟理論上的差距,可以整理成以下三點:
(1)與技術實施無太大關連,主要與組織設置和資料所有權有關。只有少數經過挑選和認可的資料科學家才可以拜訪醫院的計算環境。該環境也是受到嚴格限制與隔離的,而其他的開發人員則在外部工作,之後才串在一起的。在開發過程有些部分為手動處理:資料整合、預處理、新增資料湖、變量選擇、ML 方法選擇、模型訓練和驗證等步驟都是手動完成的。之後內容固定才有一些自動化腳本在本地跑,但仍然稱不上符合CI/CD。以及上線之後,要去哪裡收集的資料才能把新的資料收集、整理到可以重新訓練的資料集。因為病患的資料並不都在Oravizio系統上。
(2)研究相關的有效性。對個案例研究其中一個明顯的考量包含,整個流程當中,經驗和專業知識的依賴程度多大,可以怎麼樣被量化跟驗證。相關組織在確保實施和相關流程的合規性方面投入了大量精力。如何讓工程團隊、資料團隊大家都能夠理解,在專案裡面的指標以及降低可能在溝通上的誤解。
(3)這個服務是否能夠被廣泛的使用,可能會質疑案例研究設置是否具有典型性,因為該手術是與一家醫院和一家私營公司合作進行的。因此也需要跟外部證明,資料的採樣能否同樣被其他更廣大的使用者族群採用。
總結一下該專案的學習點:
(1)反覆試驗、迭代:研究總是存在一定程度的不確定性,結果通常是通過反複試驗來實現的。例如,使用 45,000 筆患者資料進行第二次迭代,重新訓練後在一定程度上提高了模型的性能。
(2)及早加入監管策略:Oravizio 開發存在一些特殊的挑戰是與該產業規範有關。在開發醫療器械產品時,必須一開始就清楚地了解適用的監管要求並相應地確定監管策略。
(3)自動化是可實現的:根據Oravizio的案例,MLOps 自動化目標是可以實現的。自動化持續訓練管道設計,必須包括在第一次開發迭代中不存在的特定新步驟。一旦持續訓練管道自動運行,少數的手動更新是唯一需要資料工程師和資料科學家參與的流程步驟。
(4)開發交接:剛剛講到開發環境的交接,一旦模型被打包並生成一份驗證報告,這些工件就可以從受限的環境當中,交付給另一個開發團隊。整個開發流程也會更順暢。而有pipeline的導入之後,開發團隊也可以透過自動化設置,在不同的臨床環境,例如醫院或者相關醫療環境可以進行相關的開發跟研究。
希望者兩篇的案例討論,可以讓大家更認識醫療產業的用戶案例。
Reference
[1]. MLOps in Healthcare | Major Use cases of MLOps in Healthcare
[2]. Machine Learning Trends to Watch Out in 2020 and 2021


 iThome鐵人賽
iThome鐵人賽